What They Are & How They Affect SEO
- Digital MarketingNews
- July 18, 2023
- No Comment
- 119
[ad_1]
What Is Crawlability?
The crawlability of a webpage refers to how simply search engines like google and yahoo (like Google) can uncover the web page.
Google discovers webpages via a course of known as crawling. It makes use of pc applications known as net crawlers (additionally known as bots or spiders). These applications observe hyperlinks between pages to find new or up to date pages.
Indexing often follows crawling.
What Is Indexability?
The indexability of a webpage means search engines like google and yahoo (like Google) are in a position so as to add the web page to their index.
The method of including a webpage to an index is named indexing. It means Google analyzes the web page and its content material and provides it to a database of billions of pages (known as the Google index).
How Do Crawlability and Indexability Have an effect on search engine optimization?
Each crawlability and indexability are essential for search engine optimization.
Here is a easy illustration exhibiting how Google works:
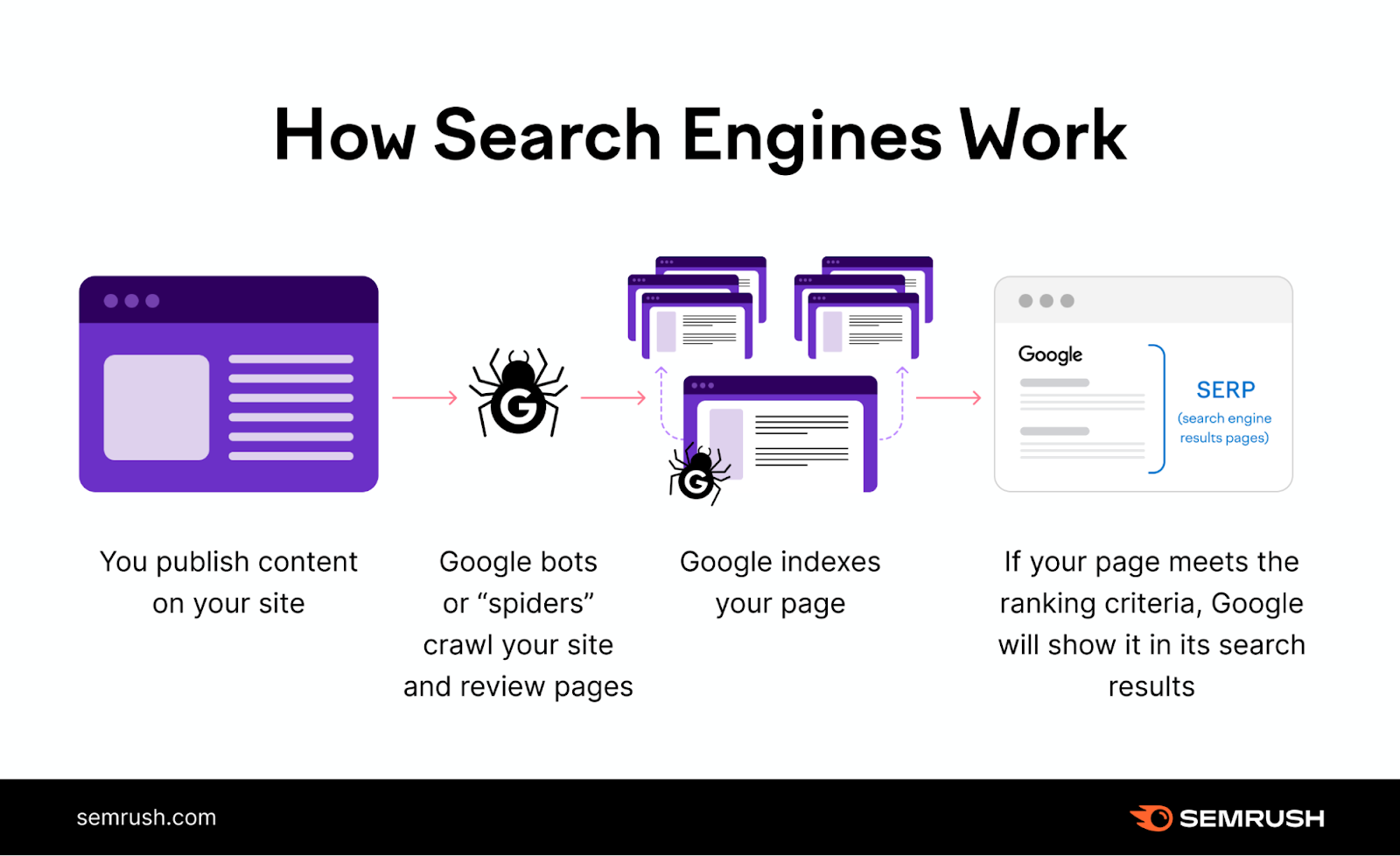
First, Google crawls the web page. Then it indexes it. Solely then can it rank the web page for related search queries.
In different phrases: With out first being crawled and listed, the web page is not going to be ranked by Google. No rankings = no search visitors.
Matt Cutts, Google’s former head of net spam, explains the method on this video:

It is no shock that an vital a part of search engine optimization is ensuring your web site’s pages are crawlable and indexable.
However how do you try this?
Begin by conducting a technical SEO audit of your web site.
Use Semrush’s Site Audit software that can assist you uncover crawlability and indexability issues. (We’ll deal with this intimately later in this post.)
What Impacts Crawlability and Indexability?
Inner Hyperlinks
Internal links have a direct influence on the crawlability and indexability of your web site.
Keep in mind—search engines like google and yahoo use bots to crawl and uncover webpages. Inner hyperlinks act as a roadmap, guiding the bots from one web page to a different inside your web site.

Nicely-placed inner hyperlinks make it simpler for search engine bots to seek out your entire web site’s pages.
So, guarantee each web page in your web site is linked from some other place inside your web site.
Begin by together with a navigation menu, footer hyperlinks, and contextual hyperlinks inside your content material.
If you happen to’re within the early levels of web site improvement, making a logical site structure also can show you how to arrange a powerful inner linking basis.
A logical web site construction organizes your web site into classes. Then these classes hyperlink out to particular person pages in your web site.
Like so:
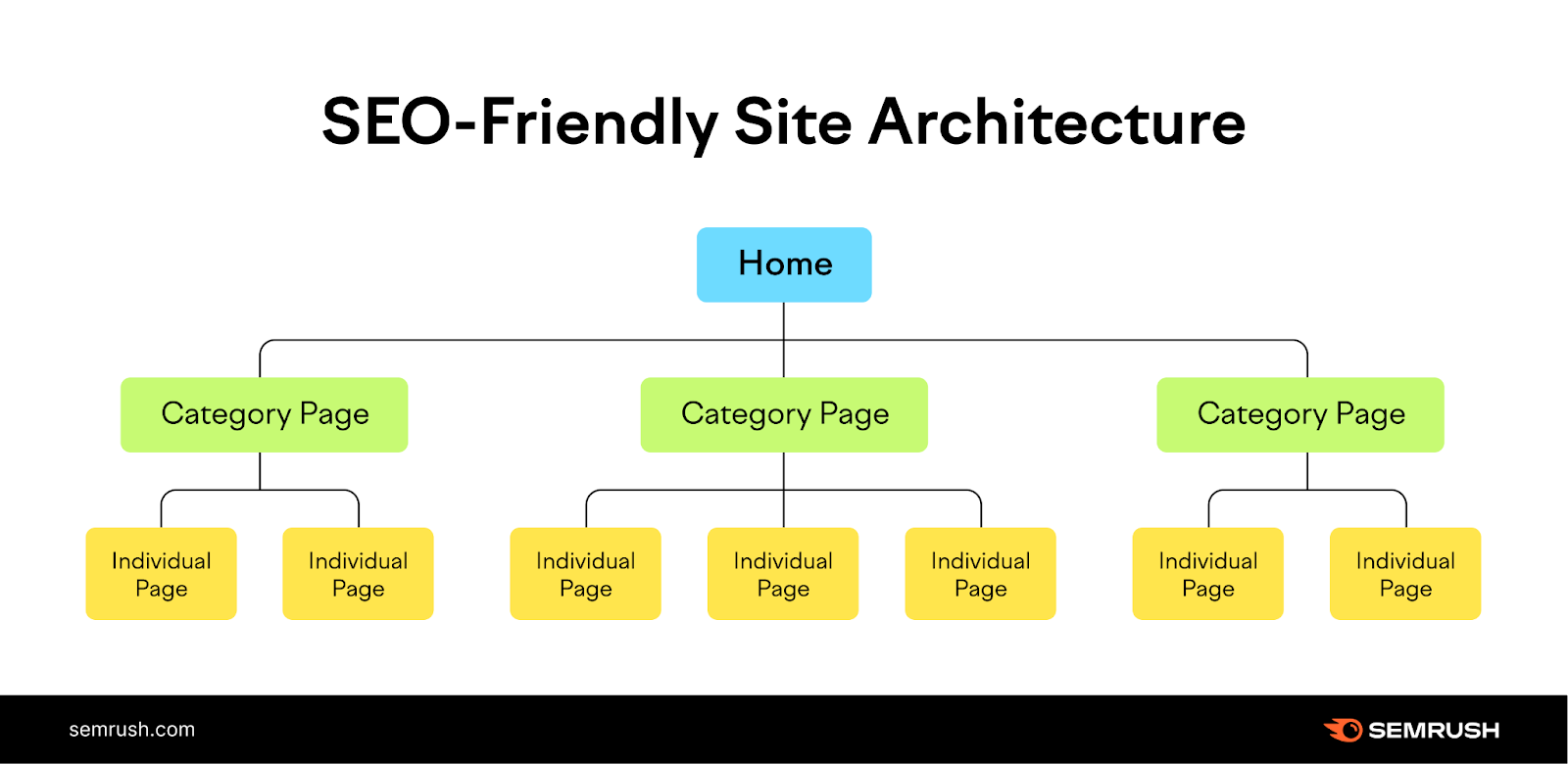
The homepage connects to pages for every class. Then, pages for every class connect with particular subpages on the positioning.
By adapting this construction, you will construct a stable basis for search engines like google and yahoo to simply navigate and index your content material.
Robots.txt
Robots.txt is sort of a bouncer on the entrance of a celebration.
It is a file in your web site that tells search engine bots which pages they will entry.
Right here’s a pattern robots.txt file:
Person-agent: *
Permit:/weblog/
Disallow:/weblog/admin/
Let’s perceive every element of this file.
- Person-agent: *: This line specifies that the foundations apply to all search engine bots
- Permit: /weblog/: This directive permits search engine bots to crawl pages inside the “/weblog/” listing. In different phrases, all of the weblog posts are allowed to be crawled
- Disallow: /weblog/admin/: This directive tells search engine bots to not crawl the executive space of the weblog
When search engines like google and yahoo ship their bots to discover your web site, they first test the robots.txt file to test for restrictions.
Watch out to not by accident block vital pages you need search engines like google and yahoo to seek out. Equivalent to your weblog posts and common web site pages.
Additionally, though robots.txt controls crawl accessibility, it does not straight influence the indexability of your web site.
Search engines like google and yahoo can nonetheless uncover and index pages which can be linked from different web sites, even when these pages are blocked within the robots.txt file.
To make sure sure pages, equivalent to pay-per-click (PPC) touchdown pages and “thanks” pages, will not be listed, implement a “noindex” tag.
Learn our information to meta robots tag to find out about this tag and the right way to implement it.
XML Sitemap
Your XML sitemap performs a vital position in enhancing the crawlability and indexability of your web site.
It exhibits search engine bots all of the vital pages in your web site that you really want crawled and listed.
It is like giving them a treasure map to find your content material extra simply.
So, embrace all of your important pages in your sitemap. Together with ones that is perhaps onerous to seek out via common navigation.
This ensures search engine bots can crawl and index your web site effectively.
Content material High quality
Content material high quality impacts how search engines like google and yahoo crawl and index your web site.
Search engine bots love high-quality content material. When your content material is well-written, informative, and related to customers, it might entice extra consideration from search engines like google and yahoo.
Search engines like google and yahoo need to ship the very best outcomes to their customers. In order that they prioritize crawling and indexing pages with top-notch content material.
Deal with creating unique, precious, and well-written content material.
Use correct formatting, clear headings, and arranged construction to make it straightforward for search engine bots to crawl and perceive your content material.
For extra recommendation on creating top-notch content material, take a look at our information to quality content.
Technical Points
Technical points can stop search engine bots from successfully crawling and indexing your web site.
In case your web site has sluggish web page load instances, damaged hyperlinks, or redirect loops, it might hinder bots’ capacity to navigate your web site.
Technical points also can stop search engines like google and yahoo from correctly indexing your webpages.
For example, in case your web site has duplicate content material points or is utilizing canonical tags improperly, search engines like google and yahoo could wrestle to grasp which model of a web page to index and rank.
Points like these are detrimental to your web site’s search engine visibility. Establish and repair these points as quickly as attainable.
Discover Crawlability and Indexability Points
Use Semrush’s Site Audit software to seek out technical issues that affect your website’s crawlability and indexability.
The software will help you discover and repair issues like:
- Duplicate content material
- Redirect loops
- Damaged inner hyperlinks
- Server-side errors
And extra.
To begin, enter your web site URL and click on “Begin Audit.”

Subsequent, configure your audit settings. As soon as completed, click on “Begin Website Audit.”

The software will start auditing your web site for technical points. After completion, it’ll present an summary of your web site’s technical well being with a “Website Well being” metric.

This measures the general technical well being of your web site on a scale from 0 to 100.
To see points associated to crawlability and indexability, navigate to “Crawlability” and click on “View particulars.”

This may open an in depth report that highlights points affecting your web site’s crawlability and indexability.

Click on on the horizontal bar graph subsequent to every subject merchandise. The software will present you all of the affected pages.

If you happen to’re uncertain of the right way to repair a selected subject, click on the “Why and the right way to repair it” hyperlink.
You’ll see a brief description of the difficulty and recommendation on the right way to repair it.

By addressing every subject promptly and sustaining a technically sound web site, you will enhance crawlability, assist guarantee correct indexation, and improve your probabilities of rating larger.
Enhance Crawlability and Indexability
Submit Sitemap to Google
Submitting your sitemap file to Google helps get your pages crawled and listed.
If you happen to don’t have already got a sitemap, create one utilizing a sitemap generator software like XML Sitemaps.
Open the software, enter your web site URL, and click on “Begin.”

The software will robotically generate a sitemap for you.
Obtain your sitemap and add it to the foundation listing of your web site.
For instance, in case your web site is www.instance.com, then your sitemap needs to be situated at www.instance.com/sitemap.xml.
As soon as your sitemap is stay, submit it to Google by way of your Google Search Console (GSC) account.
Don’t have GSC arrange? Learn our guide to Google Search Console to get began.
After activation, navigate to “Sitemaps” from the sidebar. Enter your sitemap URL and click on “Submit.”

This improves the crawlability and indexation of your web site.
Strengthen Inner Hyperlinks
The crawlability and indexability of a web site additionally lies inside its inner linking construction.
Repair points associated to inner hyperlinks, equivalent to damaged inner hyperlinks and orphaned pages (i.e., pages with no inner hyperlinks), and strengthen your inner linking construction.
Use Semrush’s Site Audit software for this objective.
Go to the “Points” tab and seek for “damaged.” The software will show any damaged inner hyperlinks in your web site.

Click on “XXX inner hyperlinks are damaged” to view an inventory of damaged inner hyperlinks.

To deal with the damaged hyperlinks, you may restore the damaged web page. Or implement a 301 redirect to the related, various web page in your web site
Now to seek out orphan pages, return to the problems tab and seek for “orphan.”

The software will present whether or not your web site has any orphan pages. Tackle this subject by creating inner hyperlinks that time to these pages.
Repeatedly Replace and Add New Content material
Repeatedly updating and including new content material is very helpful on your web site’s crawlability and indexability.
Search engines like google and yahoo love contemporary content material. While you recurrently replace and add new content material, it alerts that your web site is energetic.
This will encourage search engine bots to crawl your web site extra regularly, guaranteeing they seize the newest updates.
Purpose to replace your web site with new content material at common intervals, if attainable.
Whether or not publishing new weblog posts or updating present ones, this helps search engine bots keep engaged together with your web site and preserve your content material contemporary of their index.
Keep away from Duplicate Content material
Avoiding duplicate content material is crucial for enhancing the crawlability and indexability of your web site.
Duplicate content material can confuse search engine bots and waste crawling resources.
When similar or very related content material exists on a number of pages of your web site, search engines like google and yahoo could wrestle to find out which model to crawl and index.
So guarantee every web page in your web site has distinctive content material. Keep away from copying and pasting content material from different sources, and do not duplicate your personal content material throughout a number of pages.
Use Semrush’s Site Audit software to test your web site for duplicate content material.
Within the “Points” tab, seek for “duplicate content material.”

If you happen to discover duplicate pages, think about consolidating them right into a single web page. And redirect the duplicate pages to the consolidated one.
Or you can use canonical tags. The canonical tag specifies the popular web page that search engines like google and yahoo ought to think about for indexing.
Log File Analyzer
Semrush’s Log File Analyzer can present you ways Google’s search engine bot (Googlebot) crawls your web site. And show you how to spot any errors it would encounter within the course of.

Begin by importing the entry log file of your web site and wait whereas the software analyzes your file.
An entry log file incorporates an inventory of all requests that bots and customers have despatched to your web site. Learn our guide on where to find the access log file to get began.
Google Search Console
Google Search Console is a free software from Google that allows you to monitor the indexation standing of your web site.

See whether or not all of your web site pages are listed. And establish the explanation why some pages aren’t.

Website Audit
Site Audit software is your closest ally on the subject of optimizing your web site for crawlability and indexability.
The software studies on quite a lot of points, together with many who have an effect on a web site’s crawlability and indexability.

Make Crawlability and Indexability Your Precedence
Step one of optimizing your web site for search engines like google and yahoo is guaranteeing it’s crawable and indexable.
If it isn’t, your pages received’t present up in search outcomes. And also you received’t obtain natural visitors.
The Site Audit software and Log File Analyzer will help you discover and repair points regarding crawlability and indexation.
Sign up without cost.
[ad_2]
Source link