What Is Robots.Txt & Why It Matters for SEO
- Digital MarketingNews
- June 3, 2023
- No Comment
- 127
[ad_1]
What Is a Robots.txt File?
Robots.txt is a textual content file with directions for search engine robots telling them which pages they need to and should not crawl.
These directions are specified by “permitting” or “disallowing” the conduct of sure (or all) bots.
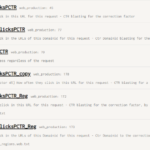
A robots.txt file appears like this:

Robots.txt recordsdata may appear difficult, however the syntax (laptop language) is simple. We’ll get into these particulars later.
On this article we’ll cowl:
- Why robots.txt recordsdata are essential
- How robots.txt recordsdata work
- Methods to create a robots.txt file
- Robots.txt greatest practices
Why Is Robots.txt Necessary?
A robots.txt file helps handle internet crawler actions in order that they don’t overwork your web site or index pages not meant for public view.
Beneath are just a few causes to make use of a robots.txt file:
1. Optimize Crawl Finances
Crawl finances refers back to the variety of pages Google will crawl in your website inside a given timeframe. The quantity can fluctuate primarily based in your website’s measurement, well being, and variety of backlinks.
In case your web site’s variety of pages exceeds your website’s crawl finances, you possibly can have unindexed pages in your website.
Unindexed pages received’t rank, and in the end, you’ll waste time creating pages customers received’t see.
Blocking pointless pages with robots.txt permits Googlebot (Google’s internet crawler) to spend extra crawl finances on pages that matter.
Word: Most web site homeowners don’t want to fret an excessive amount of about crawl finances, according to Google. That is primarily a priority for bigger websites with hundreds of URLs.
2. Block Duplicate and Non-Public Pages
Crawl bots don’t have to sift by each web page in your website.As a result of not all of them had been created to be served within the search engine outcomes pages (SERPs).
Like staging websites, inner search outcomes pages, duplicate pages, or login pages. Some content material administration methods deal with these inner pages for you.
WordPress, for instance, robotically disallows the login web page /wp-admin/ for all crawlers.
Robots.txt lets you block these pages from crawlers.
3. Cover Assets
Generally you wish to exclude assets comparable to PDFs, movies, and pictures from search outcomes.
To maintain them non-public or have Google deal with extra essential content material.
In both case, robots.txt retains them from being crawled (and due to this fact listed).
How Does a Robots.txt File Work?
Robots.txt recordsdata inform search engine bots which URLs they will crawl and, extra importantly, which of them to disregard.
Serps serve two principal functions:
- Crawling the online to find content material
- Indexing and delivering content material to searchers searching for info
As they crawl webpages, search engine bots uncover and comply with hyperlinks. This course of takes them from website A to website B to website C throughout tens of millions of hyperlinks, pages, and web sites.
But when a bot finds a robots.txt file, it’s going to learn it earlier than doing the rest.
The syntax is simple.
Assign guidelines by figuring out the user-agent (the search engine bot), adopted by the directives (the foundations).
You can even use the asterisk (*) wildcard to assign directives to each user-agent, which applies the rule for all bots.
For instance, the under instruction permits all bots besides DuckDuckGo to crawl your website:

Word: Though a robots.txt file gives directions, it could possibly’t implement them. Consider it as a code of conduct. Good bots (like search engine bots) will comply with the foundations, however unhealthy bots (like spam bots) will ignore them.
Semrush bots crawl the online to assemble insights for our web site optimization instruments, comparable to Site Audit, Backlink Audit, On Page SEO Checker, and extra.
Our bots respect the foundations outlined in your robots.txt file.
In case you block our bots from crawling your web site, they received’t.
Nevertheless it additionally means you may’t use a few of our instruments to their full potential.
For instance, in case you blocked our SiteAuditBot from crawling your web site, you couldn’t audit your website with our Site Audit tool. To investigate and repair technical points in your website.

In case you blocked our SemrushBot-SI from crawling your website, you couldn’t use the On Page SEO Checker instrument successfully.
And also you’d lose out on producing optimization concepts to enhance your webpage rankings.

Methods to Discover a Robots.txt File
The robots.txt file is hosted in your server, identical to some other file in your web site.
View the robots.txt file for any given web site by typing the complete URL for the homepage and including “/robots.txt” on the finish. Like this: https://semrush.com/robots.txt.

Word: A robots.txt file ought to all the time reside on the root area stage. For www.instance.com, the robots.txt file lives at www.instance.com/robots.txt. Place it anyplace else, and crawlers could assume you don’t have one.
Earlier than studying how one can create a robots.txt file, let’s take a look at their syntax.
Robots.txt Syntax
A robots.txt file is made up of:
- A number of blocks of “directives” (guidelines)
- Every with a specified “user-agent” (search engine bot)
- And an “permit” or “disallow” instruction
A easy block can seem like this:
Consumer-agent: Googlebot
Disallow: /not-for-google
Consumer-agent: DuckDuckBot
Disallow: /not-for-duckduckgo
Sitemap: https://www.yourwebsite.com/sitemap.xml
The Consumer-Agent Directive
The primary line of each directives block is the user-agent, which identifies the crawler.
If you wish to inform Googlebot to not crawl your WordPress admin web page, for instance, your directive will begin with:
Consumer-agent: Googlebot
Disallow: /wp-admin/
Word: Most search engines have multiple crawlers. They use totally different crawlers for normal indexing, pictures, movies, and so on.
When a number of directives are current, the bot could select essentially the most particular block of directives accessible.
Let’s say you could have three units of directives: one for *, one for Googlebot, and one for Googlebot-Picture.
If the Googlebot-Information consumer agent crawls your website, it’s going to comply with the Googlebot directives.
However, the Googlebot-Picture consumer agent will comply with the extra particular Googlebot-Picture directives.
The Disallow Robots.txt Directive
The second line of a robots.txt directive is the “Disallow” line.
You may have a number of disallow directives that specify which components of your website the crawler can’t entry.
An empty “Disallow” line means you’re not disallowing something—a crawler can entry all sections of your website.
For instance, in case you wished to permit all engines like google to crawl your complete website, your block would seem like this:
Consumer-agent: *
Enable: /
In case you wished to dam all engines like google from crawling your website, your block would seem like this:
Consumer-agent: *
Disallow: /
Word: Directives comparable to “Enable” and “Disallow” aren’t case-sensitive. However the values inside every directive are.
For instance, /picture/ is just not the identical as /Photograph/.
Nonetheless, you usually discover “Enable” and “Disallow” directives capitalized to make the file simpler for people to learn.
The Enable Directive
The “Enable” directive permits engines like google to crawl a subdirectory or particular web page, even in an in any other case disallowed listing.
For instance, if you wish to stop Googlebot from accessing each submit in your weblog aside from one, your directive may seem like this:
Consumer-agent: Googlebot
Disallow: /weblog
Enable: /weblog/example-post
Word: Not all engines like google acknowledge this command. However Google and Bing do assist this directive.
The Sitemap Directive
The Sitemap directive tells engines like google—particularly Bing, Yandex, and Google—the place to seek out your XML sitemap.
Sitemaps usually embody the pages you need engines like google to crawl and index.
This directive lives on the high or backside of a robots.txt file and appears like this:

Including a Sitemap directive to your robots.txt file is a fast different. However, you may (and will) additionally submit your XML sitemap to every search engine utilizing their webmaster instruments.
Serps will crawl your website finally, however submitting a sitemap hastens the crawling course of.
Crawl-Delay Directive
The crawl-delay directive instructs crawlers to delay their crawl charges. To keep away from overtaxing a server (i.e., decelerate your web site).
Google now not helps the crawl-delay directive. If you wish to set your crawl charge for Googlebot, you’ll need to do it in Search Console.
Bing and Yandex, however, do assist the crawl-delay directive. Right here’s how one can use it.
Let’s say you desire a crawler to attend 10 seconds after every crawl motion. Set the delay to 10, like so:
Consumer-agent: *
Crawl-delay: 10
Noindex Directive
The robots.txt file tells a bot what it could possibly or can’t crawl, however it could possibly’t inform a search engine which URLs to not index and present in search outcomes.
The web page will nonetheless present up in search outcomes, however the bot received’t know what’s on it, so your web page will appear as if this:

Google by no means formally supported this directive, however on September 1, 2019, Google introduced that this directive is not supported.
If you wish to reliably exclude a web page or file from showing in search outcomes, keep away from this directive altogether and use a meta robots noindex tag.
Methods to Create a Robots.txt File
Use a robots.txt generator tool or create one your self.
Right here’s how:
1. Create a File and Identify It Robots.txt
Begin by opening a .txt doc inside a text editor or internet browser.
Word: Don’t use a phrase processor, as they usually save recordsdata in a proprietary format that may add random characters.
Subsequent, title the doc robots.txt.
Now you’re prepared to begin typing directives.
2. Add Directives to the Robots.txt File
A robots.txt file consists of a number of teams of directives, and every group consists of a number of traces of directions.
Every group begins with a “user-agent” and has the next info:
- Who the group applies to (the user-agent)
- Which directories (pages) or recordsdata the agent can entry
- Which directories (pages) or recordsdata the agent can’t entry
- A sitemap (non-compulsory) to inform engines like google which pages and recordsdata you deem essential
Crawlers ignore traces that don’t match these directives.
For instance, let’s say you don’t need Google crawling your /shoppers/ listing as a result of it’s only for inner use.
The primary group would look one thing like this:
Consumer-agent: Googlebot
Disallow: /shoppers/
Extra directions may be added in a separate line under, like so:
Consumer-agent: Googlebot
Disallow: /shoppers/
Disallow: /not-for-google
When you’re accomplished with Google’s particular directions, hit enter twice to create a brand new group of directives.
Let’s make this one for all engines like google and forestall them from crawling your /archive/ and /assist/ directories as a result of they’re for inner use solely.
It might seem like this:
Consumer-agent: Googlebot
Disallow: /shoppers/
Disallow: /not-for-google
Consumer-agent: *
Disallow: /archive/
Disallow: /assist/
When you’re completed, add your sitemap.
Your completed robots.txt file would look one thing like this:
Consumer-agent: Googlebot
Disallow: /shoppers/
Disallow: /not-for-google
Consumer-agent: *
Disallow: /archive/
Disallow: /assist/
Sitemap: https://www.yourwebsite.com/sitemap.xml
Save your robots.txt file. Bear in mind, it have to be named robots.txt.
Word: Crawlers learn from high to backside and match with the primary most particular group of guidelines. So, begin your robots.txt file with particular consumer brokers first, after which transfer on to the extra common wildcard (*) that matches all crawlers.
3. Add the Robots.txt File
After you’ve saved the robots.txt file to your laptop, add it to your website and make it accessible for engines like google to crawl.
Sadly, there’s no common instrument for this step.
Importing the robots.txt file depends upon your website’s file construction and hosting.
Search on-line or attain out to your internet hosting supplier for assistance on importing your robots.txt file.
For instance, you may seek for “add robots.txt file to WordPress.”
Beneath are some articles explaining how one can add your robots.txt file in the most well-liked platforms:
After importing, examine if anybody can see it and if Google can learn it.
Right here’s how.
4. Take a look at Your Robots.txt
First, check whether or not your robots.txt file is publicly accessible (i.e., if it was uploaded accurately).
Open a personal window in your browser and seek for your robots.txt file.
For instance, https://semrush.com/robots.txt.

In case you see your robots.txt file with the content material you added, you’re prepared to check the markup (HTML code).
Google provides two choices for testing robots.txt markup:
- The robots.txt Tester in Search Console
- Google’s open-source robots.txt library (superior)
As a result of the second choice is geared towards superior builders, let’s check your robots.txt file in Search Console.
Word: You should have a Search Console account set as much as check your robots.txt file.
Go to the robots.txt Tester and click on on “Open robots.txt Tester.”

In case you haven’t linked your web site to your Google Search Console account, you’ll want so as to add a property first.

Then, confirm you’re the website’s actual proprietor.

Word: Google is planning to close down this setup wizard. So sooner or later, you’ll need to immediately confirm your property within the Search Console. Learn our full guide to Google Search Console to learn the way.
When you have present verified properties, choose one from the drop-down record on the Tester’s homepage.

The Tester will establish syntax warnings or logic errors.
And show the entire variety of warnings and errors under the editor.

You may edit errors or warnings immediately on the web page and retest as you go.
Any modifications made on the web page aren’t saved to your website. The instrument doesn’t change the precise file in your website. It solely checks towards the copy hosted within the instrument.
To implement any modifications, copy and paste the edited check copy into the robots.txt file in your website.
Semrush’s Site Audit instrument can examine for points concerning your robots.txt file.
First, set up a project in the tool and audit your web site.
As soon as full, navigate to the “Points” tab and seek for “robots.txt.”

Click on on the “Robots.txt file has format errors” hyperlink if it seems that your file has format errors.

You’ll see a listing of particular invalid traces.

You may click on “Why and how one can repair it” to get particular directions on how one can repair the error.

Checking your robots.txt file for points is essential, as even minor errors can negatively have an effect on your website’s indexability.
Robots.txt Greatest Practices
Use New Strains for Every Directive
Every directive ought to sit on a brand new line.
In any other case, engines like google received’t be capable to learn them, and your directions can be ignored.
Incorrect:
Consumer-agent: * Disallow: /admin/
Disallow: /listing/
Appropriate:
Consumer-agent: *
Disallow: /admin/
Disallow: /listing/
Use Every Consumer-Agent As soon as
Bots don’t thoughts in case you enter the identical user-agent a number of instances.
However referencing it solely as soon as retains issues neat and easy. And reduces the possibility of human error.
Complicated:
Consumer-agent: Googlebot
Disallow: /example-page
Consumer-agent: Googlebot
Disallow: /example-page-2
Discover how the Googlebot user-agent is listed twice.
Clear:
Consumer-agent: Googlebot
Disallow: /example-page
Disallow: /example-page-2
Within the first instance, Google would nonetheless comply with the directions and never crawl both web page.
However writing all directives beneath the identical user-agent is cleaner and helps you keep organized.
Use Wildcards to Make clear Instructions
You should utilize wildcards (*) to use a directive to all user-agents and match URL patterns.
For instance, to stop engines like google from accessing URLs with parameters, you possibly can technically record them out one after the other.
However that’s inefficient. You may simplify your instructions with a wildcard.
Inefficient:
Consumer-agent: *
Disallow: /sneakers/vans?
Disallow: /sneakers/nike?
Disallow: /sneakers/adidas?
Environment friendly:
Consumer-agent: *
Disallow: /sneakers/*?
The above instance blocks all search engine bots from crawling all URLs beneath the /sneakers/ subfolder with a query mark.
Use ‘$’ to Point out the Finish of a URL
Including the “$” signifies the tip of a URL.
For instance, if you wish to block engines like google from crawling all .jpg recordsdata in your website, you may record them individually.
However that will be inefficient.
Inefficient:
Consumer-agent: *
Disallow: /photo-a.jpg
Disallow: /photo-b.jpg
Disallow: /photo-c.jpg
As an alternative, add the “$” function, like so:
Environment friendly:
Consumer-agent: *
Disallow: /*.jpg$
Word: On this instance, /canine.jpg can’t be crawled, however /canine.jpg?p=32414 may be as a result of it doesn’t finish with “.jpg.”
The “$” expression is a useful function in particular circumstances such because the above. Nevertheless it may also be harmful.
You may simply unblock belongings you didn’t imply to, so be prudent in its utility.
Crawlers ignore all the pieces that begins with a hash (#).
So, builders usually use a hash so as to add a remark within the robots.txt file. It helps hold the file organized and simple to learn.
So as to add a remark, start the road with a hash (#).
Like this:
Consumer-agent: *
#Touchdown Pages
Disallow: /touchdown/
Disallow: /lp/
#Recordsdata
Disallow: /recordsdata/
Disallow: /private-files/
#Web sites
Enable: /web site/*
Disallow: /web site/search/*
Builders often embody humorous messages in robots.txt recordsdata as a result of they know customers not often see them.
For instance, YouTube’s robots.txt file reads: “Created within the distant future (the yr 2000) after the robotic rebellion of the mid 90’s which worn out all people.”

And Nike’s robots.txt reads “simply crawl it” (a nod to its “simply do it” tagline) and its brand.

Use Separate Robots.txt Recordsdata for Completely different Subdomains
Robots.txt recordsdata management crawling conduct solely on the subdomain during which they’re hosted.
To manage crawling on a unique subdomain, you’ll want a separate robots.txt file.
So, in case your principal website lives on area.com and your weblog lives on the subdomain weblog.area.com, you’d want two robots.txt recordsdata.
One for the principle area’s root listing and the opposite to your weblog’s root listing.
Hold Studying
Now that you’ve a great understanding of how robots.txt recordsdata work, listed below are just a few further assets to proceed studying:
[ad_2]
Source link