

The ultimate guide to robots.txt • Yoast
- AppDigital MarketingNews
- July 4, 2023
- No Comment
- 163
[ad_1]
The robots.txt file is without doubt one of the fundamental methods of telling a search engine the place it may possibly and might’t go in your web site. All main engines like google assist its primary performance, however some reply to further guidelines, which could be useful too. This information covers all of the methods to make use of robots.txt in your web site.
Warning!
Any errors you make in your robots.txt can critically hurt your web site, so learn and perceive this text earlier than diving in.
Desk of contents
What is a robots.txt file?
A robots.txt file is a plain textual content doc situated in a web site’s root listing, serving as a set of directions to look engine bots. Additionally known as the Robots Exclusion Protocol, the robots.txt file outcomes from a consensus amongst early search engine builders. It’s not an official commonplace set by any requirements group, though all main engines like google adhere to it.
Robots.txt specifies which pages or sections needs to be crawled and listed and which needs to be ignored. This file helps web site house owners management the conduct of search engine crawlers, permitting them to handle entry, restrict indexing to particular areas, and regulate crawling fee. Whereas it’s a public doc, compliance with its directives is voluntary, however it’s a highly effective software for guiding search engine bots and influencing the indexing course of.
A primary robots.txt file would possibly look one thing like this:
Person-Agent: *
Disallow:
Sitemap: https://www.instance.com/sitemap_index.xmlWhat does the robots.txt file do?
Serps uncover and index the net by crawling pages. As they crawl, they uncover and observe hyperlinks. This takes them from web site A to web site B to web site C, and so forth. However earlier than a search engine visits any web page on a site it hasn’t encountered, it would open that area’s robots.txt file. That lets them know which URLs on that web site they’re allowed to go to (and which of them they’re not).
Learn extra: Bot traffic: What it is and why you should care about it »
The place ought to I put my robots.txt file?
The robots.txt file ought to at all times be on the root of your area. So in case your area is www.instance.com, the crawler ought to discover it at https://www.instance.com/robots.txt.
It’s additionally important that your robots.txt file is known as robots.txt. The identify is case-sensitive, so get that proper, or it received’t work.
Yoast search engine optimisation and robots.txt
Our plugin has wise defaults, however you’ll be able to at all times change issues as you see match. Yoast SEO provides a user-friendly interface to edit the robots.txt file with no need to entry it manually. With Yoast search engine optimisation, you’ll be able to entry and configure the robots.txt characteristic by way of the plugin’s settings. It permits you to embrace or exclude particular web site areas from being crawled by engines like google. When utilized in conjuncture with the crawl settings,
Professionals and cons of utilizing robots.txt
Professional: managing crawl price range
It’s usually understood {that a} search spider arrives at a web site with a pre-determined “allowance” for what number of pages it would crawl (or how a lot useful resource/time it’ll spend, based mostly on a web site’s authority/measurement/popularity, and the way effectively the server responds). SEOs name this the crawl price range.
In the event you assume your web site has issues with crawl price range, blocking engines like google from ‘losing’ vitality on unimportant elements of your web site would possibly imply focusing as an alternative on the sections that matter. Use the crawl cleanup settings in Yoast SEO to assist Google crawls what issues.
It may possibly generally be helpful to dam the various search engines from crawling problematic sections of your web site, particularly on websites the place a variety of search engine optimisation clean-up must be finished. When you’ve tidied issues up, you’ll be able to allow them to again in.
A observe on blocking question parameters
One scenario the place crawl price range is essential is when your web site makes use of a variety of question string parameters to filter or type lists. Let’s say you’ve got ten completely different question parameters, every with completely different values that can be utilized in any mixture (like t-shirts in a number of colours and sizes). This results in many attainable legitimate URLs, all of which could get crawled. Blocking question parameters from being crawled will assist make sure the search engine solely spiders your web site’s fundamental URLs and received’t go into the big spider trap you’d in any other case create.
Con: not eradicating a web page from search outcomes
Though you should use the robots.txt file to inform a crawler the place it may possibly’t go in your web site, you can’t use it to say to a search engine which URLs to not present within the search outcomes – in different phrases, blocking it received’t cease it from being listed. If the search engine finds sufficient hyperlinks to that URL, it would embrace it; it would simply not know what’s on that web page. So your outcome will appear like this:

Use a meta robots noindex tag if you wish to reliably block a web page from showing within the search outcomes. That implies that to seek out the noindex tag, the search engine has to have the ability to entry that web page, so don’t block it with robots.txt.
Con: not spreading hyperlink worth
If a search engine can’t crawl a web page, it may possibly’t unfold the hyperlink worth throughout the hyperlinks on that web page. It’s a dead-end once you’ve blocked a web page in robots.txt. Any hyperlink worth which could have flowed to (and thru) that web page is misplaced.
Robots.txt syntax
A robots.txt file consists of a number of blocks of directives, every beginning with a user-agent line. The “user-agent” is the identify of the particular spider it addresses. You possibly can have one block for all engines like google, utilizing a wildcard for the user-agent, or explicit blocks for explicit engines like google. A search engine spider will at all times choose the block that finest matches its identify.
These blocks appear like this (don’t be scared, we’ll clarify beneath):
Person-agent: *
Disallow: /Person-agent: Googlebot
Disallow:Person-agent: bingbot
Disallow: /not-for-bing/
Directives like Enable and Disallow shouldn’t be case-sensitive, so it’s as much as you to put in writing them in lowercase or capitalize them. The values are case-sensitive, so /photograph/ shouldn’t be the identical as /Picture/. We like capitalizing directives as a result of it makes the file simpler (for people) to learn.
The user-agent directive
The primary bit of each block of directives is the user-agent, which identifies a selected spider. The user-agent discipline matches with that particular spider’s (often longer) user-agent, so, as an illustration, the commonest spider from Google has the next user-agent:
Mozilla/5.0 (suitable; Googlebot/2.1; +http://www.google.com/bot.html)
If you wish to inform this crawler what to do, a comparatively easy Person-agent: Googlebot line will do the trick.
Most engines like google have a number of spiders. They are going to use a selected spider for his or her regular index, advert packages, photos, movies, and many others.
Serps at all times select essentially the most particular block of directives they will discover. Say you’ve got three units of directives: one for *, one for Googlebot and one for Googlebot-Information. If a bot comes by whose user-agent is Googlebot-Video, it would observe the Googlebot restrictions. A bot with the user-agent Googlebot-Information would use extra particular Googlebot-Information directives.
The commonest person brokers for search engine spiders
Right here’s a listing of the user-agents you should use in your robots.txt file to match essentially the most generally used engines like google:
| Search engine | Area | Person-agent |
|---|---|---|
| Baidu | Basic | baiduspider |
| Baidu | Photos | baiduspider-image |
| Baidu | Cellular | baiduspider-mobile |
| Baidu | Information | baiduspider-news |
| Baidu | Video | baiduspider-video |
| Bing | Basic | bingbot |
| Bing | Basic | msnbot |
| Bing | Photos & Video | msnbot-media |
| Bing | Adverts | adidxbot |
| Basic | Googlebot |
|
| Photos | Googlebot-Picture |
|
| Cellular | Googlebot-Cellular |
|
| Information | Googlebot-Information |
|
| Video | Googlebot-Video |
|
| Ecommerce | Storebot-Google |
|
| AdSense | Mediapartners-Google |
|
| AdWords | AdsBot-Google |
|
| Yahoo! | Basic | slurp |
| Yandex | Basic | yandex |
The disallow directive
The second line in any block of directives is the Disallow line. You possibly can have a number of of those traces, specifying which elements of the positioning the required spider can’t entry. An empty Disallow line means you’re not disallowing something so {that a} spider can entry all sections of your web site.
The instance beneath would block all engines like google that “hear” to robots.txt from crawling your web site.
Person-agent: *
Disallow: /
The instance beneath would enable all engines like google to crawl your web site by dropping a single character.
Person-agent: *
Disallow:
The instance beneath would block Google from crawling the Picture listing in your web site – and all the pieces in it.
Person-agent: googlebot
Disallow: /Picture
This implies all of the subdirectories of the /Picture listing would additionally not be spidered. It will not block Google from crawling the /photograph listing, as these traces are case-sensitive.
This is able to additionally block Google from accessing URLs containing /Picture, akin to /Pictures/.
How one can use wildcards/common expressions
“Formally,” the robots.txt commonplace doesn’t assist common expressions or wildcards; nonetheless, all main engines like google perceive it. This implies you should use traces like this to dam teams of information:
Disallow: /*.php
Disallow: /copyrighted-images/*.jpg
Within the instance above, * is expanded to no matter filename it matches. Word that the remainder of the road remains to be case-sensitive, so the second line above is not going to block a file known as /copyrighted-images/instance.JPG from being crawled.
Some engines like google, like Google, enable for extra sophisticated common expressions however remember that different engines like google may not perceive this logic. Essentially the most helpful characteristic this provides is the $, which signifies the top of a URL. Within the following instance, you’ll be able to see what this does:
Disallow: /*.php$
This implies /index.php can’t be listed, however /index.php?p=1 might be. After all, that is solely helpful in very particular circumstances and fairly harmful: it’s simple to unblock belongings you didn’t need to.
Non-standard robots.txt crawl directives
Along with the generally used Disallow and Person-agent directives, there are just a few different crawl directives obtainable for robots.txt information. Nevertheless, it’s essential to notice that not all search engine crawlers assist these directives, so it’s important to grasp their limitations and concerns earlier than implementing them.
The enable directive
Whereas not within the unique “specification,” there was early discuss of an enable directive. Most engines like google appear to grasp it, and it permits for easy and really readable directives like this:
Disallow: /wp-admin/
Enable: /wp-admin/admin-ajax.php
The one different manner of reaching the identical outcome with out an enable directive, would have been to particularly disallow each single file within the wp-admin folder.
The crawl-delay directive
Crawl-delay is an unofficial addition to the usual, and few engines like google adhere to it. At the very least Google and Yandex don’t use it, with Bing being unclear. In principle, as crawlers could be fairly crawl-hungry, you might attempt the crawl-delay path to gradual them down.
A line just like the one beneath would instruct these engines like google to vary how ceaselessly they’ll request pages in your web site.
crawl-delay: 10
Do take care when utilizing the crawl-delay directive. By setting a crawl delay of ten seconds, you solely enable these engines like google to entry 8,640 pages a day. This might sound a lot for a small web site, but it surely isn’t a lot for big websites. Alternatively, should you get subsequent to no site visitors from these engines like google, it could be a great way to avoid wasting bandwidth.
The sitemap directive for XML Sitemaps
Utilizing the sitemap directive, you’ll be able to inform engines like google – Bing, Yandex, and Google – the place to seek out your XML sitemap. You possibly can, after all, submit your XML sitemaps to every search engine utilizing their webmaster instruments. We strongly advocate you achieve this as a result of webmaster instruments provides you with a ton of details about your web site. In the event you don’t need to do this, including a sitemap line to your robots.txt is a fast different. Yoast search engine optimisation robotically provides a hyperlink to your sitemap should you let it generate a robots.txt file. On an present robots.txt file, you’ll be able to add the rule by hand through the file editor within the Instruments part.
Sitemap: https://www.instance.com/my-sitemap.xml
Don’t block CSS and JS information in robots.txt
Since 2015, Google Search Console has warned web site house owners not to block CSS and JS files. We’ve informed you an identical factor for ages: don’t block CSS and JS information in your robots.txt. Allow us to clarify why you shouldn’t block these particular information from Googlebot.
By blocking CSS and JavaScript information, you’re stopping Google from checking in case your web site works accurately. In the event you block CSS and JavaScript information in yourrobots.txt file, Google can’t render your web site as meant. Now, Google can’t perceive your web site, which could end in decrease rankings. Furthermore, even instruments like Ahrefs render internet pages and execute JavaScript. So, don’t block JavaScript if you’d like your favourite search engine optimisation instruments to work.
This aligns completely with the overall assumption that Google has grow to be extra “human.” Google needs to see your web site like a human customer would, so it may possibly distinguish the primary parts from the extras. Google needs to know if JavaScript enhances the person expertise or ruins it.
Take a look at and repair in Google Search Console
Google helps you discover and repair points along with your robots.txt, as an illustration, within the Web page Indexing part in Google Search Console. Choose the Blocked by robots.txt choice:
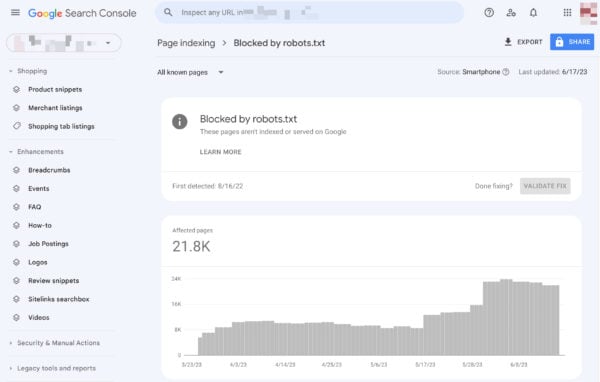
Unblocking blocked sources comes right down to altering your robots.txt file. It’s good to set that file up in order that it doesn’t disallow Google to entry your web site’s CSS and JavaScript information anymore. In the event you’re on WordPress and use Yoast search engine optimisation, you are able to do this directly with our Yoast SEO plugin.
Validate your robots.txt
Varied instruments may also help you validate your robots.txt, however we at all times want to go to the supply when validating crawl directives. Google has a robots.txt testing tool in its Google Search Console (underneath the ‘Outdated model’ menu), and we’d extremely advocate utilizing that:
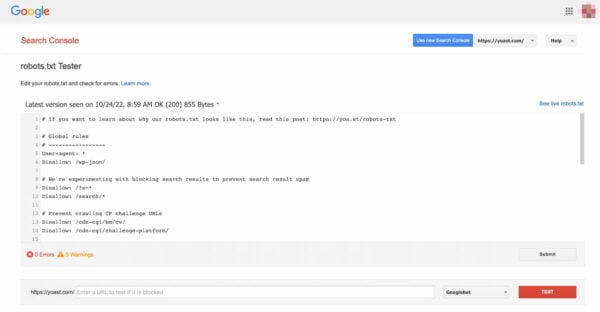
Remember to take a look at your adjustments totally earlier than you set them stay! You wouldn’t be the primary to by accident use robots.txt to dam your whole web site and slip into search engine oblivion!
Behind the scenes of a robots.txt parser
In 2019, Google announced they have been making their robots.txt parser open supply. If you wish to get into the nuts and bolts, you’ll be able to see how their code works (and even use it your self or suggest modifications).
Joost de Valk is an web entrepreneur and the founding father of Yoast. After the sale of Yoast to Newfold Digital in 2021 he has stopped being energetic in 2023. Joost, collectively together with his spouse Marieke, actively invests in and advises a number of startups by way of their firm Emilia Capital.

[ad_2]
Source link









