

How to use Google entities and GPT-4 to create article outlines
- Digital MarketingNews
- June 6, 2023
- No Comment
- 96
[ad_1]
On this article, you’ll learn to use some scraping and Google’s Data Graph to do automated immediate engineering that generates an overview and abstract for an article that, if properly written, will include many key elements to rank properly.
On the root of issues, we’re telling GPT-4 to provide an article define based mostly on a key phrase and the highest entities they’ve discovered on a well-ranking web page of your alternative.
The entities are ordered by their salience rating.
“Why salience rating?” you may ask.
Google describes salience of their API docs as:
“The salience rating for an entity offers details about the significance or centrality of that entity to your complete doc textual content. Scores nearer to 0 are much less salient, whereas scores nearer to 1.0 are extremely salient.”
Appears a reasonably good metric to make use of to affect which entities ought to exist in a bit of content material you may wish to write, doesn’t it?
Getting began
There are two methods you may go about this:
- Spend about 5 minutes (perhaps 10 if that you must arrange your pc) and run the scripts out of your machine, or…
- Jump to the Colab I created and begin taking part in round straight away.
I’m a fan of the primary, however I’ve additionally jumped to a Colab or two in my day. 😀
Assuming you’re nonetheless right here and wish to get this arrange by yourself machine however don’t but have Python put in or an IDE (Built-in Improvement Atmosphere), I’ll direct you first to a fast learn on setting your machine up to use Jupyter Notebook. It shouldn’t take greater than about 5 minutes.
Now, it’s time to get going!
Utilizing Google entities and GPT-4 to create article outlines
To make this simple to comply with alongside, I’m going to format the instructions as follows:
- Step: A quick description of the step we’re on.
- Code: The code to finish that step.
- Rationalization: A brief clarification of what the code is doing.
Step 1: Inform me what you need
Earlier than we dive into creating the outlines, we have to outline what we wish.
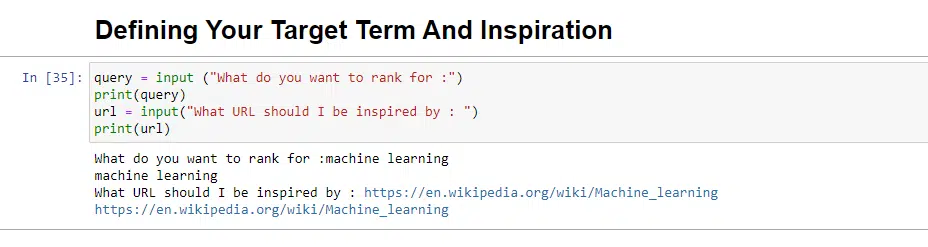
question = enter ("What do you wish to rank for :")
print(question)
url = enter("What URL ought to I be impressed by : ")
print(url)When run, this block will immediate the consumer (most likely you) to enter the question you’d just like the article to rank for/be about, in addition to provide you with a spot to place within the URL of an article you’d like your piece to be impressed by.
I’d counsel an article that ranks properly, is in a format that may work to your web site, and that you simply assume is well-deserving of the rankings by the article’s worth alone and never simply the energy of the location.
When run, it would appear like:
Step 2: Putting in the required libraries
Subsequent, we should set up all of the libraries we’ll use to make the magic occur.
!pip set up google-cloud-language beautifulsoup4 openai
!pip set up wandb --upgrade
!pip set up --force-reinstall -Iv protobuf==3.20.00
import requests
import json
from bs4 import BeautifulSoup
from google.cloud import language_v1
from google.oauth2 import service_account
import os
import openai
import pandas as pd
import wandbWe’re putting in the next libraries:
- Requests: This library permits making HTTP requests to retrieve content material from web sites or net APIs.
- JSON: It offers features to work with JSON information, together with parsing JSON strings into Python objects and serializing Python objects into JSON strings.
- BeautifulSoup: This library is used for net scraping functions. It helps in parsing and navigating HTML or XML paperwork and extracting related data from them.
- Google.cloud.language_v1: It’s a library from Google Cloud that gives pure language processing capabilities. It permits for the performing varied duties like sentiment evaluation, entity recognition, and syntax evaluation on textual content information.
- Google.oauth2.service_account: This library is a part of the Google OAuth2 Python package deal. It offers assist for authenticating with Google APIs utilizing a service account, which is a approach to grant restricted entry to the sources of a Google Cloud undertaking.
- OS: This library offers a approach to work together with the working system. It permits accessing varied functionalities like file operations, atmosphere variables, and course of administration.
- OpenAI: This library is the OpenAI Python package deal. It offers an interface to work together with OpenAI’s language fashions, together with GPT-4 (and three). It permits builders to generate textual content, carry out textual content completions, and extra.
- Pandas: It’s a highly effective library for information manipulation and evaluation. It offers information buildings and features to effectively deal with and analyze structured information, similar to tables or CSV recordsdata.
- WandB: This library stands for “Weights & Biases” and is a instrument for experiment monitoring and visualization. It helps log and visualize the metrics, hyperparameters, and different vital points of machine studying experiments.
When run, it seems to be like this:

Get the every day e-newsletter search entrepreneurs depend on.
Step 3: Authentication
I’m going to need to sidetrack us for a second to move off and get our authentication in place. We’ll want an OpenAI API key and Google Data Graph Search credentials.
It will solely take a couple of minutes.
Getting your OpenAI API
At current, you probably have to join the waitlist. I am fortunate to have entry to the API early, and so I’m scripting this that will help you get arrange as quickly as you get it.
The signup pictures are from GPT-3 and will likely be up to date for GPT-4 as soon as the move is on the market to all.
Earlier than you should use GPT-4, you may want an API key to entry it.
To get one, merely head over to OpenAI’s product page, and click on Get began.

Select your signup technique (I selected Google) and run via the verification course of. You will want entry to a telephone that may obtain texts for this step.
As soon as that is full, you may create an API key. That is so OpenAI can join your scripts to your account.
They have to know who’s doing what and decide if and the way a lot they need to cost you for what you are doing.
OpenAI pricing
Upon signing up, you get a $5 credit score which can get you surprisingly far should you’re simply experimenting.
As of this writing, the pricing previous that’s:

Creating your OpenAI key
To create your key, click on in your profile within the prime proper and select View API keys.

…and then you definitely’ll create your key.
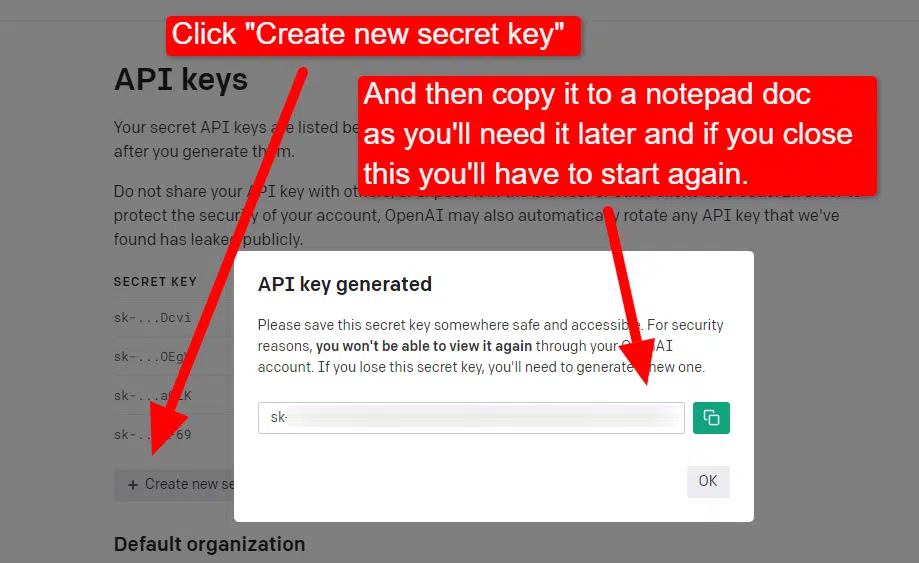
When you shut the lightbox, you may’t view your key and should recreate it, so for this undertaking, merely copy it to a Notepad doc to make use of shortly.
Observe: Do not save your key (a Notepad doc in your desktop shouldn’t be extremely safe). As soon as you’ve got used it momentarily, shut the Notepad doc with out saving it.
Getting your Google Cloud authentication
First, you’ll have to log in to your Google account. (You are on an website positioning web site, so I assume you will have one. 🙂)
When you’ve executed that, you may evaluate the Knowledge Graph API info should you really feel so inclined or jump right to the API Console and get going.
When you’re on the console:
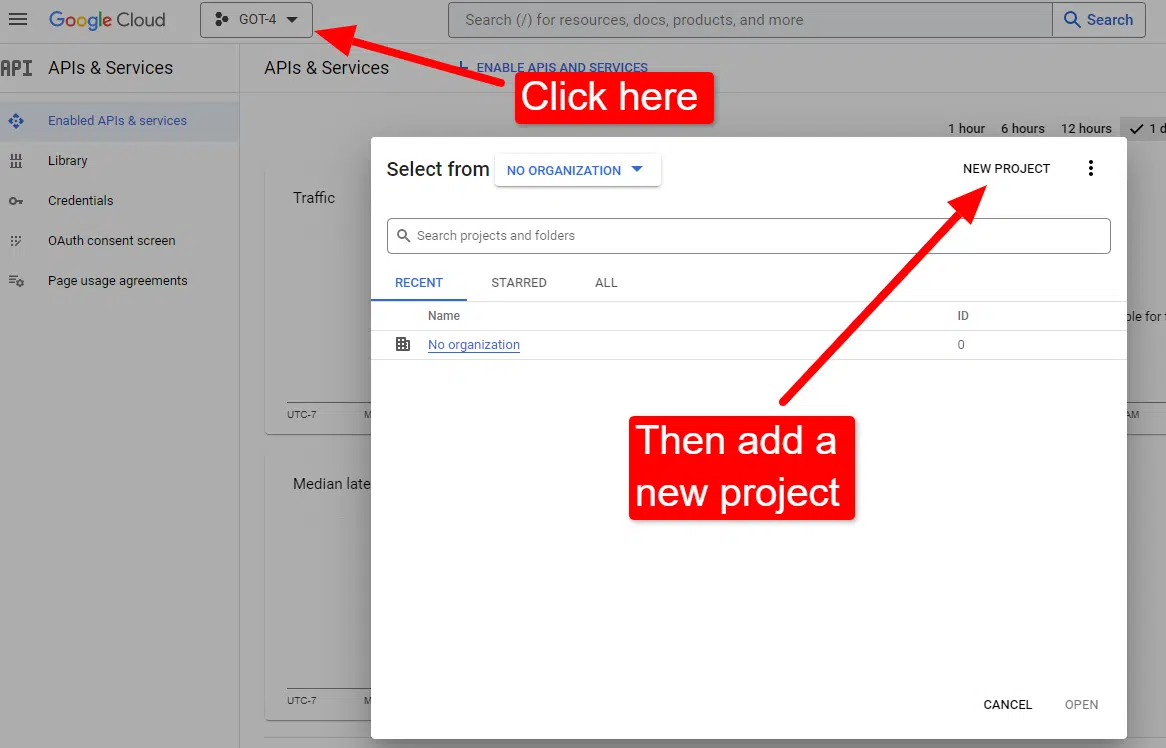
Title it one thing like “Dave’s Superior Articles.” You realize… simple to recollect.
Subsequent, you’ll allow the API by clicking Allow APIs and companies.

Discover the Data Graph Search API, and allow it.
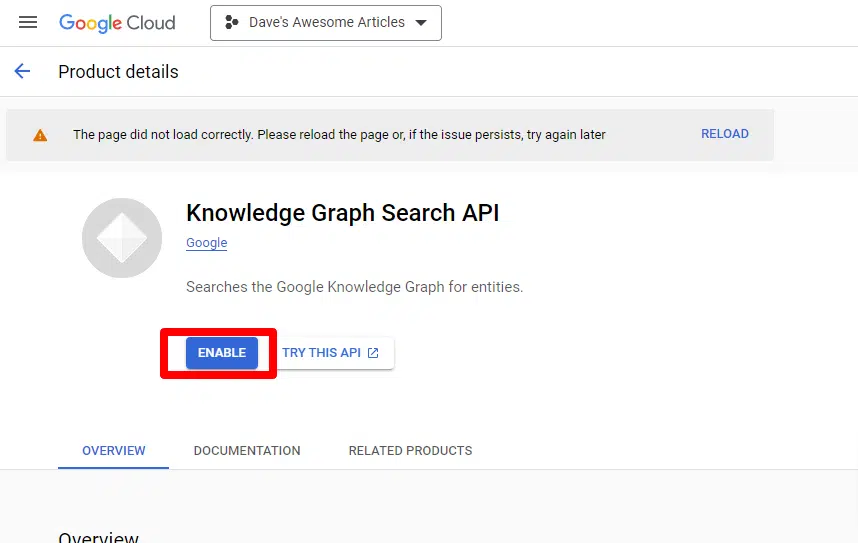
You’ll then be taken again to the primary API web page, the place you may create credentials:

And we’ll be making a service account.

Merely create a service account:

Fill within the required data:

(You’ll want to offer it a reputation and grant it proprietor privileges.)
Now we have now our service account. All that’s left is to create our key.
Click on the three dots below Actions and click on Handle keys.

Click on Add key then Create new key:

The important thing sort will likely be JSON.
Instantly, you’ll see it obtain to your default obtain location.
This key will give entry to your APIs, so hold it secure, identical to your OpenAI API.
Alright… and we’re again. Able to proceed with our script?
Now that we have now them, we have to outline our API key and path to the downloaded file. The code to do that is:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON'
%env OPENAI_API_KEY=YOUR_OPENAI_API_KEY
openai.api_key = os.environ.get("OPENAI_API_KEY")You’ll substitute YOUR_OPENAI_API_KEY with your individual key.
Additionally, you will substitute /PATH-TO-FILE/FILENAME.JSON with the trail to the service account key you simply downloaded, together with the file identify.
Run the cell and also you’re prepared to maneuver on.
Step 4: Create the features
Subsequent, we’ll create the features to:
- Scrape the webpage we entered above.
- Analyze the content material and extract the entities.
- Generate an article utilizing GPT-4.
#The operate to scrape the online web page
def scrape_url(url):
response = requests.get(url)
soup = BeautifulSoup(response.content material, "html.parser")
paragraphs = soup.find_all("p")
textual content = " ".be a part of([p.get_text() for p in paragraphs])
return textual content#The operate to drag and analyze the entities on the web page utilizing Google's Data Graph API
def analyze_content(content material):
consumer = language_v1.LanguageServiceClient()
response = consumer.analyze_entities(
request="doc": language_v1.Doc(content material=content material, type_=language_v1.Doc.Kind.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8
)
top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10]
for entity in top_entities:
print(entity.identify)
return top_entities#The operate to generate the content material
def generate_article(content material):
openai.api_key = os.environ["OPENAI_API_KEY"]
response = openai.ChatCompletion.create(
messages = ["role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well.",
"role": "user", "content": content],
mannequin="gpt-4",
max_tokens=1500, #The utmost with GPT-3 is 4096 together with the immediate
n=1, #What number of outcomes to provide per immediate
#best_of=1 #When n>1 completions could be run server-side and the "greatest" used
cease=None,
temperature=0.8 #A quantity between 0 and a couple of, the place larger numbers add randomness
)
return response.selections[0].message.content material.strip()That is just about precisely what the feedback describe. We’re creating three features for the needs outlined above.
Eager eyes will discover:
messages = ["role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well.",You can edit the content (You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well.) and describe the role you want ChatGPT to take. You can also add tone (e.g., “You are a friendly writer …”).
Step 5: Scrape the URL and print the entities
Now we’re getting our hands dirty. It’s time to:
- Scrape the URL we entered above.
- Pull all the content that lives within paragraph tags.
- Run it through Google Knowledge Graph API.
- Output the entities for a quick preview.
Basically, you want to see anything at this stage. If you see nothing, check a different site.
content = scrape_url(url)
entities = analyze_content(content)You can see that line one calls the function that scrapes the URL we first entered. The second line analyzes the content to extract the entities and key metrics.
Part of the analyze_content function also prints a list of the entities found for quick reference and verification.
Step 6: Analyze the entities
When I first started playing around with the script, I started with 20 entities and quickly discovered that’s usually too many. But is the default (10) right?
To find out, we’ll write the data to W&B Tables for easy assessment. It’ll keep the data indefinitely for future evaluation.
First, you’ll need to take about 30 seconds to sign up. (Don’t worry, it’s free for this type of thing!) You can do so at https://wandb.ai/site.
Once you’ve done that, the code to do this is:
run = wandb.init(project="Article Summary With Entities")
columns=["Name", "Salience"]
ent_table = wandb.Desk(columns=columns)
for entity in entities:
ent_table.add_data(entity.identify, entity.salience)
run.log("Entity Desk": ent_table)
wandb.end()When run, the output seems to be like this:
And whenever you click on the hyperlink to view your run, you’ll discover:

You may see a drop in salience rating. Keep in mind that this rating calculates how vital that time period is to the web page, not the question.
When reviewing this information, you may select to regulate the variety of entities based mostly on salience, or simply whenever you see irrelevant phrases pop up.
To regulate the variety of entities, you’d head to the features cell and edit:

You’ll then have to run the cell once more and the one you ran to scrape and analyze the content material to make use of the brand new entity rely.
Step 7: Generate the article define
The second you’ve got all been ready for, it’s time to generate the article define.
That is executed in two elements. First, we have to generate the immediate by including the cell:
entity_names = [entity.name for entity in entities]
gpt_prompt = f"Create an overview for an article about question that features the next entities: ', '.be a part of(entity_names)."
print(gpt_prompt)This basically creates a immediate to generate an article:

After which, all that’s left is to generate the article define utilizing the next:
generated_article = generate_article(gpt_prompt)
print(generated_article)Which can produce one thing like:

And should you’d additionally prefer to get a abstract written up, you may add:
gpt_prompt2 = f"Write an article abstract about question for an article with an overview of: generated_article."
generated_article = generate_article(gpt_prompt2)
print(generated_article)Which can produce one thing like:

Opinions expressed on this article are these of the visitor writer and never essentially Search Engine Land. Employees authors are listed here.
[ad_2]
Source link









