

11 Crawlability Problems & How to Fix Them
- Digital MarketingNews
- July 7, 2023
- No Comment
- 191
[ad_1]
Questioning why a few of your pages don’t present up in Google?
Crawlability issues may very well be the offender.
On this information, we’ll cowl what crawlability issues are, how they have an effect on search engine optimisation, and the way to repair them.
Let’s get began.
What Are Crawlability Issues?
Crawlability issues are points that stop engines like google from accessing your web site pages.
When engines like google reminiscent of Google crawl your website, they use automated bots to learn and analyze your pages.

If there are crawlability issues, these bots could encounter obstacles that hinder their potential to correctly entry your pages.
Widespread crawlability issues embody:
- Nofollow hyperlinks
- Redirect loops
- Unhealthy website construction
- Sluggish website pace
How Do Crawlability Points Have an effect on search engine optimisation?
Crawlability issues can drastically have an effect on your search engine optimisation sport.
Search engines like google act like explorers once they crawl your web site, looking for as a lot content material as attainable.
But when your website has crawlability issues, some (or all) pages are virtually invisible to engines like google.
They will’t discover them. Which implies they’ll’t index them—i.e., save them to show in search outcomes.

This implies lack of potential search engine (natural) visitors and conversions.
Your pages should be each crawable and indexable to be able to rank in engines like google.
11 Crawlability Issues & Repair Them
1. Pages Blocked In Robots.txt
Search engines like google first take a look at your robots.txt file. This tells them which pages they’ll and can’t crawl.
In case your robots.txt file appears to be like like this, it means your complete web site is blocked from crawling:
Consumer-agent: *
Disallow: /
Fixing this downside is easy. Change the “disallow” directive with “permit.” Which ought to permit engines like google to entry your complete web site.
Consumer-agent: *
Enable: /
In different circumstances, solely sure pages or sections are blocked. As an illustration:
Consumer-agent: *
Disallow: /merchandise/
Right here, all of the pages within the “merchandise” subfolder are blocked from crawling.
Clear up this downside by eradicating the subfolder or web page specified. Search engines like google ignore the empty “disallow” directive.
Consumer-agent: *
Disallow:
Alternatively, you possibly can use the “permit” directive as a substitute of “disallow” to instruct engines like google to crawl your complete website. Like this:
Consumer-agent: *
Enable: /
Word: It’s widespread follow to dam sure pages in your robots.txt that you just don’t need to rank in engines like google, reminiscent of admin and “thanks” pages. It’s a crawlability downside solely once you block pages meant to be seen in search outcomes.
2. Nofollow Hyperlinks
The nofollow tag tells engines like google to not crawl the hyperlinks on a webpage.
The tag appears to be like like this:
<meta title="robots" content material="nofollow">
If this tag is current in your pages, the hyperlinks inside could not usually get crawled.
This creates crawlability issues in your website.
Scan your web site with Semrush’s Site Audit software to verify for nofollow hyperlinks.
Open the software, enter your web site, and click on “Begin Audit.”

The “Web site Audit Settings” window will seem.

From right here, configure the fundamental settings and click on “Begin Web site Audit.”
As soon as the audit is full, navigate to the “Points” tab and seek for “nofollow.”
To see whether or not there are nofollow hyperlinks detected in your website.

If nofollow hyperlinks are detected, click on “XXX outgoing inside hyperlinks include nofollow attribute” to view a listing of pages which have a nofollow tag.

Evaluate the pages and take away the nofollow tags in the event that they shouldn’t be there.
3. Unhealthy Web site Structure
Site architecture is how your pages are organized.
A sturdy website structure ensures each web page is just some clicks away from the homepage and there aren’t any orphan pages (i.e., pages with no internal links pointing to them). Websites with sturdy website structure guarantee engines like google can simply entry all pages.

Unhealthy website website structure can create crawlability points. Discover the instance website construction depicted beneath. It has orphan pages.

There isn’t a linked path for engines like google to entry these pages from the homepage. So they might go unnoticed when engines like google crawl the location.
The answer is simple: Create a website construction that logically organizes your pages in a hierarchy with inside hyperlinks.
Like this:

Within the instance above, the homepage hyperlinks to classes, which then hyperlink to particular person pages in your website.
And supply a transparent path for crawlers to search out all of your pages.
4. Lack of Inside Hyperlinks
Pages with out inside hyperlinks can create crawlability issues.
Search engines like google could have bother discovering these pages.
Establish your orphan pages. And add inside hyperlinks to them to keep away from crawlability points.
Discover orphan pages utilizing Semrush’s Site Audit software.
Configure the tool to run your first audit.
As soon as the audit is full full, go to the “Points” tab and seek for “orphan.”
You’ll see whether or not there are any orphan pages current in your website.

To unravel this potential downside, add inside hyperlinks to orphan pages from related pages in your website.
5. Unhealthy Sitemap Administration
A sitemap supplies a listing of pages in your website that you really want engines like google to crawl, index, and rank.
In case your sitemap excludes pages meant to be crawled, they may go unnoticed. And create crawlability points.
Clear up by recreating a sitemap that features all of the pages meant to be crawled.
A software reminiscent of XML Sitemaps may help.
Enter your web site URL, and the software will generate a sitemap for you routinely.

Then, save the file as “sitemap.xml” and add it to the foundation listing of your web site.
For instance, in case your web site is www.instance.com, then your sitemap URL ought to be accessed at www.instance.com/sitemap.xml.
Lastly, submit your sitemap to Google in your Google Search Console account.
Click on “Sitemaps” within the left-hand menu. Enter your sitemap URL and click on “Submit.”

6. ‘Noindex’ Tags
A “noindex” meta robots tag instructs engines like google to not index the web page.
The tag appears to be like like this:
<meta title="robots" content material="noindex">
Though the “noindex” tag is meant to manage indexing, it could possibly create crawlability points for those who go away it in your pages for a very long time.
Google treats long-term “noindex” tags as “nofollow,” as confirmed by Google’s John Muller.
Over time, Google will cease crawling the hyperlinks on these pages altogether.
So, in case your pages aren’t getting crawled, long-term “noindex” tags may very well be the offender.
Establish pages with a “noindex” tag utilizing Semrush’s Site Audit software.
Set up a project within the software and run your first crawl.
As soon as the crawl is full, head over to the “Points” tab and seek for “noindex.”
The software will listing pages in your website with a “noindex” tag.

Evaluate the pages and take away the “noindex” tag the place applicable.
Word: Having “noindex” tag on some pages—pay-per-click (PPC) touchdown pages and “thanks” pages, for instance—is widespread follow to maintain them out of Google’s index. It’s an issue solely once you noindex pages meant to rank in engines like google. Take away the “noindex” tag on these pages to keep away from indexability and crawlability points.
7. Sluggish Web site Velocity
Web site pace is how shortly your website masses. Sluggish website pace can negatively impression crawlability.
When search engine bots go to your website, they’ve restricted time to crawl—generally known as a crawl price range.
Sluggish website pace means it takes longer for pages to load. And reduces the variety of pages bots can crawl inside that crawl session.
Which implies necessary pages may very well be excluded from crawling.
Work to resolve this downside by enhancing your general web site efficiency and pace.
Begin with our information to page speed optimization.
8. Inside Damaged Hyperlinks
Broken links are hyperlinks that time to lifeless pages in your website.
They return a “404 error” like this:

Damaged hyperlinks can have a major impression on web site crawlability.
Search engine bots comply with hyperlinks to find and crawl extra pages in your web site.
A damaged hyperlink acts as a lifeless finish and prevents search engine bots from accessing the linked web page.
This interruption can hinder the thorough crawling of your web site.
To seek out damaged hyperlinks in your website, use the Site Audit software.
Navigate to the “Points” tab and seek for “damaged.”
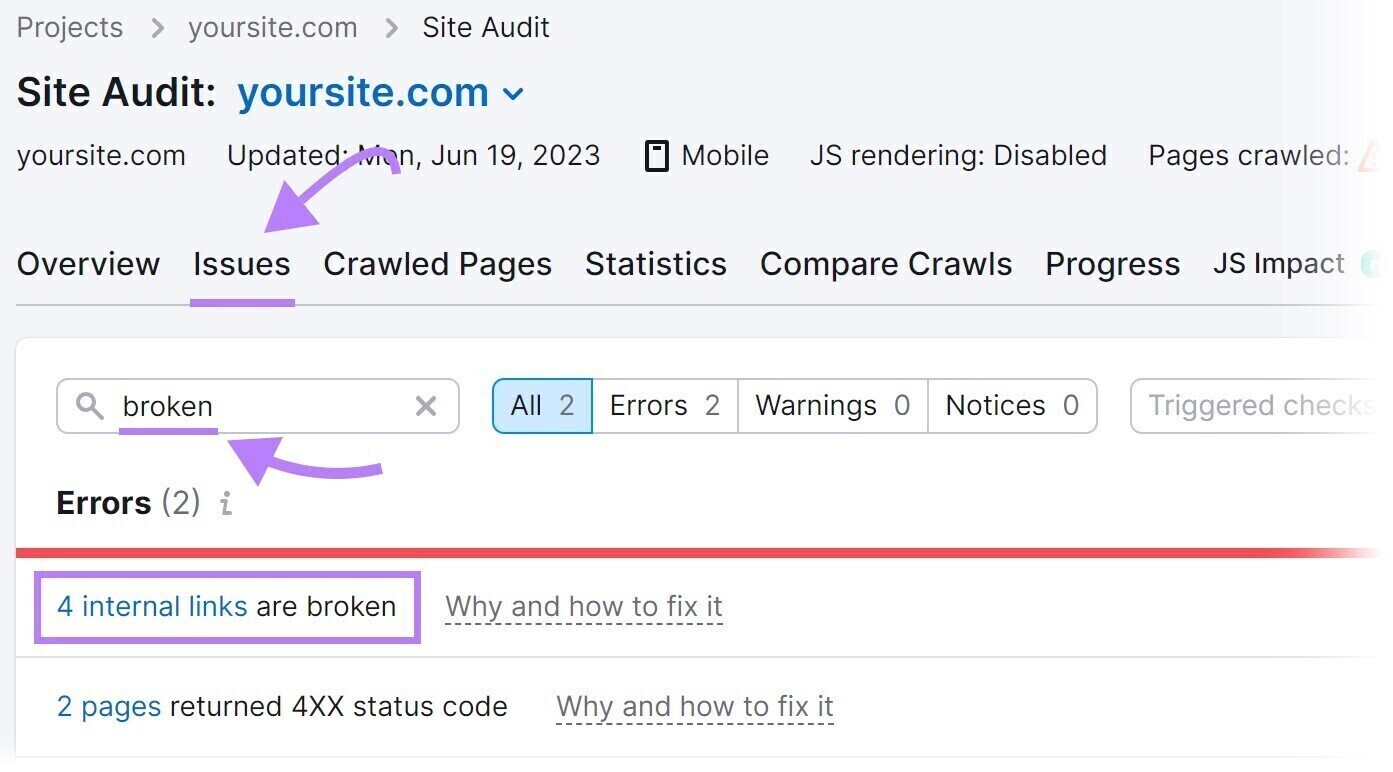
Subsequent, click on “# inside hyperlinks are damaged.” You’ll see a report itemizing all of your damaged hyperlinks.

To repair damaged hyperlinks, change the hyperlink, restore the lacking web page, or add a 301 redirect to a different related web page in your website.
9. Server-Facet Errors
Server-side errors, reminiscent of a 500 HTTP status code, disrupt the crawling course of.
Server-side errors point out that the server could not fulfill the request, which makes it tough for bots to entry and crawl your web site’s content material.
Usually monitor your web site’s server well being to determine and clear up for server-side errors.
Semrush’s Site Audit software may help.
Seek for “5xx” within the “Points” tab to verify for server-side errors.

If errors are current, click on “# pages returned a 5XX standing code” to view an entire listing of affected pages.
Then, ship this listing to your developer to configure the server correctly.
10. Redirect Loops
A redirect loop is when one web page redirects to a different, which in flip redirects again to the unique web page, forming a steady loop.

Redirect loops entice search engine bots in an limitless cycle of redirects between two (or extra) pages.
Bots proceed following redirects with out reaching the ultimate vacation spot—losing essential crawl price range time that may very well be spent on necessary pages.
Clear up by figuring out and fixing redirect loops in your website.
The Site Audit software may help.
Seek for “redirect” within the “Points” tab.

The software will show redirect loops and supply recommendation on the way to repair them.

11. Entry Restrictions
Pages with entry restrictions, reminiscent of these behind login kinds or paywalls, can stop search engine bots from crawling and indexing these pages.
In consequence, these pages could not seem in search outcomes, limiting their visibility to customers.
It is sensible to have sure pages restricted. For instance, membership-based web sites or subscription platforms typically have restricted pages which can be accessible solely to paying members or registered customers.
This permits the location to supply unique content material, particular presents, or customized experiences. To create a way of worth and incentivize customers to subscribe or turn out to be members.
But when vital parts of your web site are restricted, that’s a crawlability mistake.
Assess the need of restricted entry for every web page. Preserve restrictions on pages that actually require them. Take away restrictions on others.
Rid Your Web site of Crawlability Points
Crawlability points have an effect on your search engine optimisation efficiency.
Semrush’s Site Audit software is a one-stop resolution for detecting and fixing points that have an effect on crawlability.
Sign up at no cost to get began.
[ad_2]
Source link









